前言
阅读《深入理解java虚拟机》
正文
什么是垃圾收集器?
收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现。
Java虚拟机规范中对垃圾收集器应该如何实现没有任何规定,因此不同的厂商、不同的版本的虚拟机所提供的垃圾收集器也有很大的差异,一般都会根据用户自己的应用特点和要求使用不同的垃圾收集器。
特别名词
串行收集器:它是使用单线程进行垃圾回收,它是独占式的垃圾回收。
并行收集器:它是简单的把串行回收期多线程化。
并行:指多条垃圾收集线程并行工作,但此用户线程仍然处于等待状态;
并发:指用户线程与垃圾垃圾线程同时执行,但不一定是并行的,用户继续运行,而垃圾收集线程在另一个cpu上运行。
吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
Serial收集器(新生代收集器)
它是一个单线程收集器,使用标记-整理算法。工作过程如下:

Serial old收集器(老年代收集器)
Serial old是Serial收集器的老年版本,它同样是一个单线程的收集器,工作过程跟Serial的一样,
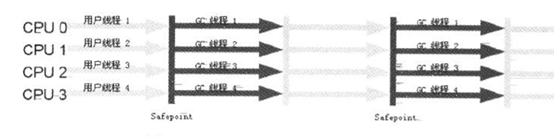
ParNew收集器(新生代收集器)
它是Serial收集器的多线程版本,实现了垃圾收集线程和用户线程同时工作,工作过程如下:
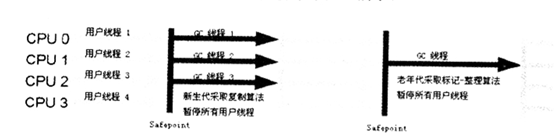
Parallel Scavenge 收集器(新生代收集器)
它是使用的复制算法的,又是并行的多线程收集器。CMS等其他收集器是关注尽可能的缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集目标则是达到一个可控的吞吐量。
Parallel Old收集器(老年代收集器)
Parallel Old是Parallel Scavenge老年代的版本,使用多线程和标记-整理算法。工作过程如下:
CMS收集器(老年代收集器)
CMS(Concurrent Mark Sweep)是一种以获取最短停顿时间为目标的收集器。CMS收集是基于标记-清除算法实现的。工作过程:1.初始标记,2.并发标记,3.重新标记,4.并发清除。如下:

G1收集器(两者都可用)
G1(Garbage-First)收集器是当今收集器技术发展最前沿的成果之一,它是一款面向服务端的垃圾收集器。
G1具有如下特点:
- 并行与并发;
- 分代收集;
- 空间整合;
- 可预测的停顿;
工作过程: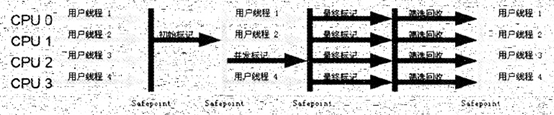
总结
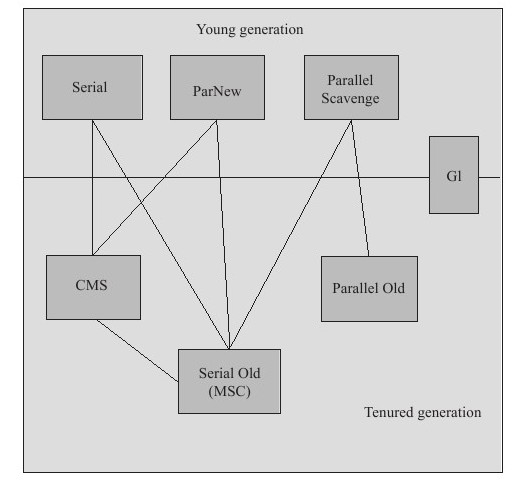
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商、版本的虚拟机所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。接下来讨论的收集器基于JDK1.7 Update 14 之后的HotSpot虚拟机(在此版本中正式提供了商用的G1收集器,之前G1仍处于实验状态),该虚拟机包含的所有收集器如下图所示:
上图展示了7种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。虚拟机所处的区域,则表示它是属于新生代收集器还是老年代收集器。Hotspot实现了如此多的收集器,正是因为目前并无完美的收集器出现,只是选择对具体应用最适合的收集器。